

|
|
|
Разделы
Публикации
Популярные
Новые
|
Главная » Оптимизация производительности transact 1 ... 36 37 38 39 40 41 42 ... 55 Горизонтальное разделение Несмотря на то что таблши была онти.чшзирована но.зностыо, вы можете решить, что оиа просто слишком больш;1я, чтобы обеспечить необходимы!! урове!!ь i!po-11.!вод1!телы10с'1!1. По .мерс добавленяи 3a!i!ice!i в таблицу системе нeoбxoди!o 110ддерж!!вать се увел1!Ч]Н!а10ШН11СЯ ра.змер. В К01!еч1!о.\1 счече оиа вырастет iia-сто.!ы<о, что одна только иавига1И1я но индексу станет очень долг!1.м нроцессо.м. Прохожден!!е В-дерева индекса, содержащего .\1!!ЛЛионы к.чюче! !, .может занять болыпе 1!ре\!е!и!, че.м получен1!е сам1!х да!!1!ых. Одно !13 рен1ен!!й этой проблемы заключается в разделении таб.чицы 1юр!13онталы!0 - можно разб!!ть ее на пескол1>ко таблиц на основа1!ни зиачеиш ! некоторого столбца или столбцов. Таким образо.м, количесию заиисеГг которое должен обработать запрос, значительно у.мепьшится. Горизонтальное разделение особенно удоб1!0 П1)п.менять и том случае, если некоторое подм!!ожество табл!1цы !!Спол1>зуется значительно больше, чем остальная таблица. Разделив ее, вы позвол1!те запроса.\!, которые ее заде11Ству!от, избежать 1геобходи1МОСТп проб!!раться через дебри данных, которые и.м !! не нуж1!ы. В отл!!Чие от верг!1кально разделенных таблиц, гор1!30!!тально разделсш!ые таб-;1ицы содержат од!н1аковые столбщя. Вот пр!1.мер, в котором горизонтал!Л10 раз-де.чяется таблица Orders 6a3iji данных Northwind па осповаи!п! зиаче1!ий месяца в столбце OrderDate: USF No.-thwTnd BEGIN TRAN -- Ч;обь' коно было отменить все нани дейсвия -- Уи&ил. индекс, чтс5ь' можно было летне ув/деть эффект разделе-ия DROP INDEX Orders.OrderDate SELECI INTO P1997Gl 0.ders FROM Orders лНЕРЕ OrderDate BETwEEN 199701СГ A.ND 199/С13Г SELECT * INTO P1997C2 0rders FRCM Orders иНЕРЕ OrderDate BLIwEEN l9970201 AND 199/0223 SELECT * INTO P199/03 Crderb FROM Orders лНЕРЕ OrderDate BETWEEN 199/0301 ANL 199/0331 SELECT INTO P199/C4 GrGers FROM Orders WHERE OrderDate BElrtEEN 199/0401 AND 1997C430 SELECT * INTO P199705 0rders FROM Orders wHERE OrderDate BEFwEEN 199/0501 AND 1997С53Г SELECT INTO Fi997C6 0raers FROM Orders WHERE OrderDaie BETwEEN 1997060Г AND 19970630 FRCM O-ce.-s WHERE OrderDcie EETWEi Ч^О'гЗГ .Г 199;0.3: SELECT * INTO P199/GS C-ce-. FROM Crde-s WHERE OrderDate EETWEEN .л'-а-У. AlD -bV-Ceil SELECT * INTO P:99-O9 0roers FRCM Orders WHERE OrcerCatc BElл:E i-v9LГ AC iiv/O-S-SELECT * INTO P1997jC 0raers FROM Orders WHERE OrderDate BETwEEN 199/1001 AND 199/1031 SELECT * INTO P199ni 0rders FROM Orders WHERE OrderDate BETWEEN 19971:31 A,\D 19971130 SELECT * INTO PI99712 Crders FROM Crder-s WHERE O-dorDdte ЬЕлЕЕп i99i121i AND 19971231 -- Тепеоь выпол-ия несксгько ae-tcccH, ч;с&-.: гос.и'регь эффект разделения SELECT ттЦспаПв:. O-wrSatc. 112, Crofrttortn. ca-Nri*) NuniOrders FROM Orders WHERE OrderDate BEiWEEN I997G70: AND 19970731 GROUP BY C0NVFRT(chcr(6;. OderDdte :i2) ORDER BY OrderMonth ALTER TABIE P199707 Cr(]ers ADO CuNSiPAlf, ТГ, Pi99707 OrdeS PRIMARY KEY (OrderlD) SELECI CCN>/ERr;crdr;6). G-dtrDdtc. :i2, OrcerMcnin. COUNT(*) NumOrders FROM Pj9970/Orders WHERE Orde-Date BETWEEN igO/G/Ol AM 19970/31 GROUP BY C0iNVERl (char(6). CrcerDdtc 112) ORDER BY OrderMortn OrderMonth .Nu:iiOrco-s 199707 33 OrderMonth NuinOrdes 199707 33 Чтобы увидеть, как сказалось разделение таблицы на производительности, давайте рассмотрим планы выполнения двух операторов SELECT в запросе (рис. 16.19 и 16.20). Запрос к разделенно!! таблице на 28 % эффективнее по затратам в области операций ввода-вывода и иа 89 % эффективнее в сфере загрузки ресурсов процессора. Очевнд]1о, для прохождения подхнюжсства таблицы необ.ходи.мо .меньше времени, чем для прохождения всей таблицы.  Рис. 16.19. План выполнения запроса в случае целой таблицы Orders it. £л- a;irdw-:-i ig а& В > f;CH OtderKS WHEfE ОгаегЗвсе iuecy 14: (j.i ry аяе (re 1 C.ve Co the ttatcJi) : 5.504 Ш atream Acegac.  CluittMBd imint Scan m  11*1  LogicAl арнЫюп: Вои count: EitHfuttBit (ow m: 1Л1 cut: CPU Kumbo ( MCMutoi-II Sut>(lDecu*t- . ........ ------ .....-- - ~. ~ - im О.чки 113 iieaocianvioB i-opii.j()iria.ibii()ro ра.ие.теии.ч -- х'ве.личенне ctcjkhocth запросов. С.тожность запросов, которые о.хватывают бо.чсе одного раздела таб-Л1ЩЫ, увеличивается лппейпо. Вы .можете избавиться от части из них. псполь-.зуя прслставлеипя для объедииечпгя разделов с по.мощыо UNION, по это пе иа-NHioro .эффективнее. Некоторое ко,тичсство допо.тинтел1>ных с.южносгеп просто неизбежно. К то.му же сложно прн.менять ограничения, исно.чьзу10ни1е сс:ылкн на са.мих себя, coit.\!ecTHo с горизонтальны.м разделением. Ес.тн для оп])еделе)1ия донустн.мостн зиаче1Н1я таблице необходн.мо ссылаться самой на себя, при налн-чин ра,злелов .может потребоваться проверить неско.тько других таблиц. Оптимизатор запросов Одна из сильных сторон современных реляционных СУБД - серверна>1 он-тн.\1нзацця запросов. Это область, в KOTOpoii клиснг-серверпые снстели.1 и.меют значительное прен.мушесгво перед одноуровиевымн база.мн даниых. Без сервера существует лиин> небольшая воз.можность опт1кмизировать затросы, выполняемые приложения.мн, особенно в случае .многопользовательских приложе1Н1Й. Мапрн.мер, нет воз.можности повторно задействовать план выполнения, построенного для запроса одного пользователя, другим пользователем. Нельзя кэпн1-ровать объекты, используемые несколькими пользователями, кроме возможностей кэширования файловой системы, поскольку никто, кроме дра11вера базы даниых, не зижт ничего о базе данных. Для операционно!! системы это п[)осто еще один файл или файлы. Для приложения же это ресурс, к которо.му оно получает доступ с HOMOLiH>io cneuHiLTbHoio дра1П!е])а. обычно ncKoii DLL. Короче говоря, никто ни за что не отвечает - никто не заботится о хранилище настолько, чтобы быть уверенны.м, что доступ к базе даниых согласован и опти.мален абсолютно для всех клиентов. Клнент-сервер1няе СУБД измен]1ли этот порядок ве-uieii, сделав сервер равны.м партнеро.м разработчика, гарантируя, что доступ к базе да1Н1ых будет максимально э(1)фектнвны.м. Научные разработки, связанные с оптимизацией запросов, развив;ин1сь года.\н1, так что сервер чаше всего способен быстрее и лучше оптн.\И13провать запрос, че.м человек. Современные онтн.М1кза-торы используют одну из онерашйт, которую компьютеры делают лучше всего, - перебор вариантов. Онтн.мнзатор может быстро перебрать различные варианты решений запроса, чтобы выбрать нз них лучший. СУБД применяют различные подходы для онтн.мн.зацин запросов. Некоторь1е способы опти.лнгзацин основаны на различн1>1Х эвристиках - внутрегне запрос переупорядочршается и перестраивается на основантн! предопределенного множества а.тгебранчсскнх правил. Деревья .запросов расчленяются, ассоциативные и ко.м.мутаттшные правила прн.мсняются в некоторо.м предопрсделенно.м по1)яд-ке, пока не будет построен план, удовлетворяющий всему запросу. Некоторые СУБД оптимизируют запросы на основании эле.чгентов синтаксиса. Это накладывает значителыюс бремя оптимизации на пользователя, потому что пред1гка-ты в иредложсши! WHERE и условиях соединений не переупорядочиваются - план выполнения каждый раз генерируется один и тот же. Поскольку под;нш-ны.м оптнлтзаторо.м в это.м случае выступает пользователь, для достижения хорошей производительности запросов требуется глубокое знание базы да]1пых. (Л.-ма!т1чсска>1 оти.мизацпя - ./го iccjpcTUierKaM .мсто.ижа, upc-aiio.iaiаклцая. что опти.мизатору известна ст]-)уктура базы даи1И>1.\ и он мож'ет провести оигп-.\п13аиию, осповьппысь па опре.теления.х orpainntennii. Несколько произволите.кт! псчледуют эту область оптимизаши! запросов, чтобы позволить архитектор} 6аз!)1 данных иеносрелствепио кои1])олн])овать процесс опти.чисииипь Самьи! pacn])ocTpaiieiHibni и, я считаю, са.мьи') ;-)<))<1юктивньи .\ютол оити.мп зации - :vro оити.\и1зация, основанная иа оценке стоимости. Стои.чюстная оп-ти.\п1зация оценивает несколько раз.шчных способов вьпи.шення запросов 11 выбирает тот, которьн'! булег выпо.чиягься .ме1иллес вре.мя. Сгон.мостиой онгн-.\н1затор определяет это различие, основываясь иа опенке количества onepannii BHO.ia-BbHuvui. утилизации ресурсов процессора и д])ушх (})акторах, влияющих на производительность запросов. Как раз этот подход и ис1юльз\ет SQL Ser\er, а реализация .этого подхода в не.м - одна нз лучших в 3ioii индустрии. Я уже кратко рассматривал оптн.мизагор .запросов и некоторые его особенности в это11 главе, 1Ю считаю, что необходимо хорошо по1иг\ють, как ои работает, чтобы писать оитимтьньй! код иа Transact-SQL и гра.мотпо оити.чтзировать за-п]юсьг Оптимизация запроса состоит из нескольких шагов. Оптимизатор аиали-зирует запрос, определяет аргументы поиска (SARG) и прсдложеиня с OR, находит соедипепия и так далее. Он сравпштет различные способы осуществления иеоб.ходимых соедииенн!! и определяет индексы, которые лучше всего исиользовать в это.м запросе. Поскольку опти.\П1зат01) осиовьтается на оценке стон.чю-CTii, он выбирает метод, которьн! выполнит запрос с наиметлпилн! затрата.ми. Обычно он делает правильны!) выбор, по иногда ему надо ие.чиюго по.мочь. Оптимизация соединений SQL Server версии 7.0 и более поздние версии, по.ми.мо простых coeдинeниii с в.и)же1И1ымн шпста.мн (nested loop), и.мевшихся ранее, поддерживают и другие типы соел1И1ени11. Эта гибкость позволяет онти.\п1затору naiiTH наилучши!! способ связать одну таблицу с лруго11, используя всю доступную е.му инфор.мацию. Соединение с использованием вложенных циклов Соединения с ирнменением вложенных циюов представляют собой цикл в циюче. В соедииегнгях этого типа одна таблица применяется для внешнего цикла, другая - для виутреннщ'о. При каждо!! итерации внешнего цикла полностью проходится виутреги1ий цикл. Эта стратегия становится очень неэффективной. Запрос. использую1ШИ1 в.юженные чщк.ты, и его план выполнения показаны па рис. 16.2 L Соединение слиянием Соединения слияние.м работают значительно лучше с большими набора.ми данных, по сравнению с соедннения\п1 с при.менение.м вложенных циклов. BaiHicn 1ГЗ каждой таблицы соединения выбираются и срав1Н1ваются. Обе таблицы должны быть отсортированы по соедпняе.мым столбца.\г Опти.мизатор обычно выбирает соедтпгение слия1Н1ем, обрабатывая большие объемы данных, уже отсортированные ио соед1Ишемым столбцам. На рис. 16.22 показан запрос, который опти.мпзато]) обрабатывает с испо;1Ьзоваги1см соединения слияние.м. Ojsey 1: Ccy cost (Cirlit:ve i: bacr!, ---jj,. Рис. 16.21. Соединение с использованием вложенных циклов 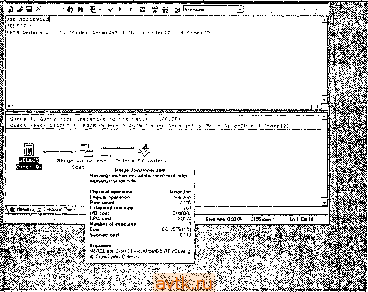 Рис. 16.22. Оптимизатор выбирает соединение слиянием, когда обе таблицы отсортированы должным образом Соединение с использованием хеширования Соединения с жтюльзозанием хеширозания также более эф(})ектннны при работе с больии1Ми наборали! данных, че.м соединения с ири.менение.м нл(Jжeниыx циклов, К ТО.М} же они работают хорошо, когда таблицы не отсортированы по столбца.м, n(j коюрьгм гц)ОВодитгя соед1ИК!иие. Сервс]) осуществляет соединение с использованием хеширования, вьишсляя хеш sannceii из .\reHbnieii таблнць] (обозначается со.здавае.\к1я , bnild-таблица) н вставляя нх в хеп1-табл1И1у, затем обрабатывает большую таблицу (<исследуе.\к1я>>, ргоЬе>>-таблииа) по одной записи, (л<анируя хеш-таблицу для поиска совпадени1г Поскольку зиачеиия лля хсш-таблииы получаются из .меньше!! табл1!ЦЬ!, размер табл1!!ил сведс!! к .мп!!1!-.му.му, а так как в.месчо реаль!1ых зиаче1!т 1 прн.меня!Отся их xei!i!!, срав!1енпе таб-Л!!Ц может 6i)!ib осуществлено очень б1>1Стро. Соединения с заде11ствование.м хеширования - вар1!ация концепции хеш-!1нлексов, которые были в некоторых СУБД на протяжени!! ряда лет. В случае с хеп!-п1!дсксами .xein-таблиць! хра1!ятся иостоя!ИИ) - они являются индщссох!. Да1!льге хешируются в слоты, которые имеют одинаковое значение хеша. Есл1! 1Н1декс и.меет у1И1кальный непрерывны!! кл!ОЧ, су!цествует .\!!!НГ!.\1алы!ая совершенная хеш-(})ункция: каждое з!!ачен!!е хешируется в спой собст!!енн!>1!1 с;!От I! .между !!И.м!! В !!иде1ссе 1!ст про.межулков. Есл!! !1!!декс ун!исалы!ьгй, 110 не непрерывны!!, .\!ожет существовать совершенн^гя хош-фуикция, которая хеширусг каждое значение в свой собственны!! слот, но .между пи.ми .мо1 ут су!цес-1вова-1!, промежутк!!. Соединение с использованием .хеширован!!Я показано на рис. 16.23.  orCh lnCi НТО CuacomersNonlmJayed fftCH Сизсотвга ! Ccde!:aNonI.-.dc? rsWoi.Indexed с jtoircrsNonlr.dexea - 3; C-Jery texE: SELtCT COHNT sNocIftdeved Cose: 0 (lencli/Inrie , ., Cose: гг.* i Т&Ые 3cai  Hflih МЫсМстм Join Ute eeCJi ION lioTt the <сф гщм ю tulu a Kuh хЛЛе. *nd earti low lti?in Ihe Ьочха iW lo vobe rto rhe Mtn l*bte. owpunng af шлсппо rowi Phyiicaf opeialion: Ron count: Eitmeled torn иго- Рис. 16.23. Соединение с использованием хеширования хорошо работает с большими объемами данных, которые могут быть не отсортированы Способы оптимизации с использованием индексов в доиолиспие к применению гп1дексов с оп()Знанны.\и1 аргу.%и;ига.\и1 ноиска оп-ти.\и1загор .может также испо;1ьзоиать индексы для ускорения запросов н другн.мн сп()со6а.\п1. Некоторые из .чтн.х способов воз.можны благола[)я способности оитн.\н1.затора прп\кп1ять разные индексы одно/! п той же таблицы. Объединение индексов Как я уже утюмниал в 3roii главе, ntJKpbrnie индексо.м (inde.x covering) ~ это процесс, при котором онтнхи13атор нрн.меияет для обработки запроса некластср-иьй1 индекс вместо того, чтобы обращаться к таблице или кластерно.му индексу. Этот процесс требует, чтобл столоны, получаемые запросо.м, существовали в BH,ie ключей некластериого индекса. План вьнюлнсння, в которо.м для получения данных зале11сгвуется некластернын индекс и отсутствует поиск закладки (bookmark lookup), использует иок1)ытие тщексо.м. SQL Server .может обьедп-иять несколько иекластерных 1Н1дексои для создания покрьшаюнтх индексов налету. Чаще всего это быстрее, чем при.менение индексов по отдельности, и уж точно быстрее, че.м последовательное сканирование са.мой таблицы. На рис. 16.24 показан запрос, которьп ! оптп.\шзатор преобразовывает в объединение двух некластерных индексов. 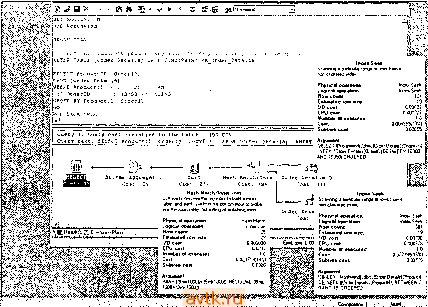 Рис. 16.24. Сервер может объединять индексы для покрытия запроса Возможность SQL Server так объед1Н1ять некластерные индексы имеет некоторые следствия, касающиеся проектировання баз данных. До изобретения объ- с.тиоимя 11илекчч)1з ouijihiijjui исдход к созданию нокрьппнощего индекса зак.ио-чался в добавлении одного или двух столбцов к существующему индексу, чтобы индекс мог покрывать дантия!! запрос !глп заиросьг 1 еиерь, когда оптп.\игзатор может обьелинягь И1щек(м)1, чаще всего разу,\и1ее р/азбивать зтц ключи на не-(ччолько индсксо!!, чтобы опги.\!нзато[) мог са.м объединять их по .мере необходи.мости. Это позво.1яет огггн.ми.затору также применять их и ио отле.щносгн, что б1лло бы иево.г\и)жн() в с.чучае cocraisnoro ключа. Эго не означает, что вы вообнге должны отказаться от соспиинлх ключе1( иидексо!!, ио вoз^южиocть разде.км1ия их па отдельные ин.тексы тоже необходи.мо учигьниггь. Слияние и пересечение индексов Подобно oбьeдииeипкJ индексов, оггги.мизатор .может осушес тв.чять слияние н ие-ресеч(ми1е тиыексов. Это позволяет оптп.\игзагору объединять соответствующие ключи из нескольких индексов во .\июжество значений ключе!!, которое затем .может б1ять использовано для поиска в кластерном ключе или таблице д.тя по-лучен1!я столбцов, которые ие на11де!1ы в 1и!лексах. Рисунок 16.25 иоказывае-! запрос со сл1!яние.м (пересечением) и!1лексов и е1Ю план выпол!1ения. Обратите внимание, что пла!! в1яг!олнс!!ия вючючаст шаг Bookinark lookup. Это оз!!ачае1-, что запрос не покр1явается 1!екластерны.М1! индскса.м!!. Од1!ако для вы-!юлнения за)!роса ири.ме!1яется нх иересечен1!е. ii5gi.s<iv>gu<>j uuiR< ALTES TkhlE JOrder teaiis) r>FOP .wVXiiT PK Orasr Oetai: 1Й (Ccdec ZtT.aiis] ].:; QL-decID :*;;:.. lOSJG 1U300 lY Ptcductxr. OrderlD UnicPcjce j BkZY. TFIAJJ O-jecv 1: Ouecy cost Icrtlecive to the bdchj : 100,00ч 0-jery ZKxzi SELE:T Froduc4:>. CccterlP, Vn-.tPz ics. fOUT.Tf) FPOH [Ocii?r Setilj] UHCRE Product Xi.t- Cr-ieclb Bl Coat; 0\ Зосс Cost: гЭ!. BooJorark Lookup Hash Hatch/Inne Otdec Pet il3.P, Cost: 13 . Costi 3B\ Coat: Ij; Ocder Details,0. Cost; l3-(  Рис. 16.25. Сервер может выполнять пересечение индексов для обработки запроса Оптимизация хранилищ данных в до110,1нет1е к инструмента.м для работы с xpanii,iiima,\!ii данных н OLAP, по-стаБЛяе,\1Ы.\1 с SQL Server, онтн.\н1загор ,занрогон ,\10)кет распознавать звездообразные схе.мы ,iaupocoB и применять ciieuiia.TbHbie ,меголы оптн.мнзацнн для ,!апрос()в, в которых соелтнногся габ.тнцы ()актов н нз.меренн!!. Поскольку таб-лнц|)1 и,з,мерсний чаще всего 6i.iBaioT ,\ткроскоппческп.\1п по сравнен1но с таб-л1Н1а.\П1 (jaKTOB, отпмн,зат()р запросов л[оже1 сгенерировать план вынолпення, в котором сначала выполняется пер(!крестное соединение всех табл]Н1 измерений запроса др\г с друго,\1, а затем результат соед]И1яетгя с таблице!) (})актоБ. В !1Т0!е !10луч!!м мсньшес кол1!чест1Ю соелинепнй но cpaiHiei!iiio с 1раднц1!0!!-!П)1лп1 ,ме10да,\!н обт.елиненпя габ.пт такого типа, Л\чте iu:ero 1)ассх!отреть это на iip!!.\iepe. Для иростогь! !1релполож11М, что у нас есть три табл1!ЦЬ!: две таблицы из.мере!Н1и !i одна таблица ()акт()в, В каждой таблице !i3.Mepe!Hiii десят1> записе!!, а в Tao.Time факто!! - ,\и1Ллио!1 занисе!!. Если вы соедините табл1!!1у фактов с дву.мя табл1!ца,\!и из.!ep(.чlнii с по.мощью !И!утре!1не!о соелн!1е!1н>1 (inner join) Н Oim!.\!!I3aT0p l!e I!pH,!eHI!T П!1КаК!1Х Д0ПС)Л!1НТеЛЬ!1Ь!Х .\!еГОДОВ 0!!ТТ1- мнзаш!!!, вь! по.тучитс лпп .мнлл!1она операции С()ед11нен1!я (од1!н миллион для соед1!!1е1!1!я таблиц1л фактов п табл!1цы перво!Ч) !13.мерения и одни .миллион для соед1!нення со BTopoii табли!1е11 пз.мерепия). Однако, если вместо зто1 о вы осу-1цестБ1!те перекрестное сослинение л1!ух таблиц 1!3,мере!1!1Й, а затем соедините таблицу (j)aKTOB с !!0лу41!!Ш1н.мся результато,м, вы у.мен1>шите число опе[)ацнй соединения 1!ри.мсрио в два раза: 10 x 10 aannceii в таблицах 1!змереиий = 100 01!ера!Н!Й соедннен1!Я -I- 1000000 операций сосдн!!СН!1я таблицы фактов и обт)едн!!е!!Ной таблицы H3.\iei)CH!iii = 1000100 Bceio операц1!Й соедннеиня Следуюшп!! кол SQL иллюстрирует т!и!1!чиое звездообразное соед!1иеиие. Снача.та в нем созда!отся таблишп из.мерени!! и таблица фактов, описанные ранее, а затем таблина (j)aiaoB соединяется с лв\.\1Я табл1!ца.\1и измерен!!!!. ПРИМЕЧАНИЕ-------- Не выполняйте этот запрос с включенной опцией Show Execution Plan (показывать план выполнения) в Query Analyzer - каждая вставка записи будет иметь отдельную часть в графическом представлении плана выполнения, построение которого займет вечность, и к тому же он будет не очень-то полезен. Если вы хотите посмотреть план выполнения этого запроса, выделите часть кода с начала и до выполнения запроса, затем нажмите сочетание кпавии! Ctrl+E в Query Analyzer, чтобы выполнить его. Это создаст таблицы и заполнит их данными. Затем нажмите комбинацию Ctrl+K, чтобы включить отображение графического представления плана выполнения, выделите сам запрос и выполните его. SEF NOCOUNT ON CREATE TABLE #clml (diml int identity PRIMARY KEY. dmlval int) CREATE TABLE #dim2 (diin2 int identity PRIMARY KEY, dirr2val int) CREATE TABLE ffacttable (kl int identity PRIMARY KEY. dini int, dirr2 int; CECIAKE (aiQCD INT .SET Cloopl 1 ... 36 37 38 39 40 41 42 ... 55 |
|
© 2004-2025 AVTK.RU. Поддержка сайта: +7 495 7950139 в тональном режиме 271761
Копирование материалов разрешено при условии активной ссылки. |
 Экструзия композитов
Экструзия композитов Угловые шкафы
Угловые шкафы Искусственная кожа
Искусственная кожа Детская кроватка
Детская кроватка Мебель для ванной
Мебель для ванной Выбираем мебель
Выбираем мебель Ткань для мебели
Ткань для мебели Подъемная кровать
Подъемная кровать Шторы для дома
Шторы для дома Поролон
Поролон