

|
|
|
Разделы
Публикации
Популярные
Новые
|
Главная » Оптимизация производительности transact 1 ... 34 35 36 37 38 39 40 ... 55 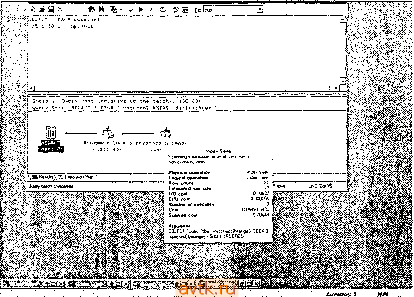 Рис. 16.9. Оптимизатор запросов корректно определяет аргументы поиска, в которых константа расположена в начале 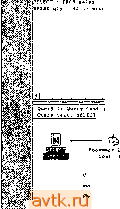 letlve to tbc becc:h : rrqb galga вверг qty > phjoical opeib logic t onqisti row и-н: etlmted (hit ; l/u cmI. ; cpu colt nunbei ot smb hmh matchninmin mca i(m ham the 1(49 rttui I3 CukI a hash litrt. ana esch ic ifoin me ьсйот w io иом OBJEa llp.*>[dboirtatwllatj-il. SEEK lisAiJi x y!-> 4010RDEHED 1Ш clintet dlimi i>sbttk . . scarnngsmiboiatfengerfiiwiunomaskji i cpuco>4: и ,---- mcu(et. aigunent: qbj£aapi.if*oii>*e>i.n.pka * !i. Рис. 16.10. План выполнения показывает объединение двух аргументов поиска с помощью операции хеширования В прош.то.м liepaueiicTiia бы.чи a.xu.uieeoBoii иягоГ! оитп.мизатора запретов -oil пе зпа.], как преобразовать Jtx в значения ключей индекса, и, следовательтю, вьиюлнял полное сканирование таблицы, чтобы обработать такие запросы. Это до сих нор происходит в некоторых СУБД, но не в SQL Server. Напри.мер. рас-с.мотрнлг следующий запрос: SZLECr * FRCM sales WHFRE qty 0 Ha рис. 16.11 гк)ка.зан по.1ученный план выполнения. Оптимизатор преобразует qty !=0 к qty < О OR qty > G Это позволяет осуществлять сравнения со зиачення.\н1 ключе11 индекса, а значит, будет применяться индекс, который .мы создали ранее, как показано в плане выполнешш. 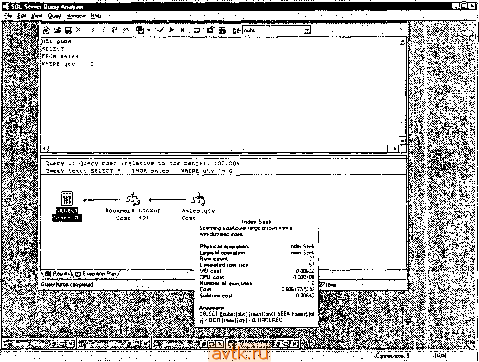 Рис. 16.11. Оптимизатор запросов знает, как оптимизировать сравнения на неравенство Вот прщмер, в котором результирующее .\нгожество фильтруется на основании частей столбца с датой - довольно частая задача, при решеншг которой подстерегает несколько ловушек: ..:r veil , ; ,: WHERF DATEFAKI (TT.C; ce-Ea:.l-,-t AND DArEPAR (yy.:rce:-C: AND (DA EAR :cc,0C!TrD(!:v Ег:л1г'; ; r-:.. } Этот запрос 110.т\-чает зак;ыы за первые rj)ii лпя >Тчаза1птого месяца. Н; М1С. 1G.12 показан пи;\пашпп1Ся п.:ап iii)mo.iuenii>i. !тзЕ N-.3rt;J;M;..-.d ш /V. Згг^ас* iGe Quecy l! Query cost irlativ- to the bALcW i 10:1.СОЧ Query taxti 3Z.LICT FFOH ОсЛегз SHERE DATSTART ,:nr:.. CrderliaiLei-5 Л1ч'Р PATEFAST 5ГЛГ г 11. tec Cost: 3 CtuilBted Index Scan PhyiicaJ оре,д1оп. UoflicaJ opei4*tion- rPIJ coit Numbei nl Cotr Subifce coil.  :C()**fi:ei)rt.,.a- .(Ж ii Рис. 16.12. План выполнения для первого варианта запроса с датой План выполпепия осуитесгвляег исх'ледовательиое скапирование класт(.р11о-го индекса, а зате.м ({фильтрует результаты в соот bctctbihi с условиялп! в предложении WHERE. Может ли онти.\ик)атор запросов использовать какое-либо ил условий в иредложеипи WHERE в качестве аргу.меита поиска? Нет, пе может. И снова столбцы т-аблицы заключены в выражеьшя у оппгмизатора пет способа узнать, что на са.мо.м деле вычис.тяет .это выражение. Вот запрос, переписанный так, чтобы опти.мизатор мог распознать аргументы поиска (рис. 16.13): dSE Nort.Twi.nd SELECT * FROM Order-s ivHERE CrderDdte BETWEEN 1593050: AND i№6G5J3 Как видите, теперь оптимизатор правильно распознает и ирн.меняет аргументы поиска в иредложеипи WHERE для фильтрации запроса. Он преобразует вы-ражииге BETWEEN к составно.му аргу.менту поиска, иснользуюп1е.му индекс OrderDate таблицы Orders. .13 . .(W . -ф-. BHEFE ordecr.ece ; s . :. i.-:c;;  r.ive CO the bbcchl ; lOO.DO* rndeit Seet icsnnr a caiOCUe; range Ы lOWl hum Phytical opeiation. Logical Dpefatun. Row count: Е 11иа1Ы WW srae. I/O co.t: CPU cott: Humbef otaxecutet: Subttee co*l. Aigument: EElC.((0,<j*f.UO.a<NOew!E£TW£EHM . 11Э38 12дайММ0мау 31933 U0CluMORDtRED  Рис. 16.13. План выполнения для улучшенной версии запроса с датой Что будет, если на.м потребуются данные более чем за три дня? Что, если на.м потребуется цельн'! .месяц? Вот нервьн ! запрос, переписанны!! для получения данных за весь месяц (рис. 16.14): USE Northwind SELECT * EROM Orders aHERE OATEPARKirni. C-dfcrDdLe; =5 AMU DAEPARKyy. OrdeCdte)=i998 A вот улучшенная версия этого запроса, измененная нодобны.м образо.м (рнс. 16.15): USE iVorthwina SELECT * FROM Crcers rtHERE OrderDate BETWEEN 19980501 AND 1996053! HirrepeccH гот факт, что улучшенная версия запроса теперь также сканирует кластерный гшдекс. Почему? Ответ - количество возвращаемых данных. Онтн-\нкзатор оценил, что будет .менее затратно нросканировать всю таблицу и отфильтровать результаты, че.м использовать некластерный индекс, ното.му что каждая за]Н1сь, на11дениая с по.мощью тптдекса, должна зате.м быть найдена в к.частерно.м индексе (и.ти в таблице, если не существует кластерного индекса), чтобы получить остальные столбцы, необходн.мые запросу. Этот пнп' в плане вьиюлнения называется Bookniark lookup* (поиск закладки; пос.мотрттте, на-нрн.мер, на рнс. 16.13). ICE Hor-,f.v;.  Рис. 16.14. Первоначальный запрос применяет последовательное сканирование кластерного индекса -.1 . - uCcr Гл-и orders ,uery Ij Cuecy coai; (celative to otic baichi ; 100.CiC Coat Sconrrig e cUMtcd ndex. e>v)e.)> uofy lange. 1Л) CM: CPU co (: ll.-iaii выио.тиеиия, li которо.м .записи иа.чодятся с ио.моицио искластсриого индекса, должен включать шаг Bookmark, если запрос возвращаег сто-юцы, ко-торы.х нет в гшдексе. В этом случае опти.ликзатор оценил расходы, связанные с этим донолиительным шаго.м, н решил, что лучше нри.метпь полное сканирование кластер!1ого индекса. В иервоначально.м запросе этот шаг был оценен как 80/и Bceii работы плана выполнения, так что это и.меет с.мыс.т. Генсрь .мы увеличили в несколько раз к();и1чество BoaBpauiae.vHiix записей, поэто.му этот ишг (Л'ал настолько долгим, что на само.м деле эффективнее будет прочитать нею таблицу. Есть несколько способов обойти эту проблему. Мы уже расс.\ютрели од1И1 - надо возвращать .меньше данных. Фактически, порог, после которого опти.\и1за-гор решает, что более эффективно применять последовательное скагнфованпс, равен данны.м за пять или больше дней в таблипе Orders - получение данных за пять или более дней приведет к сканированию кластерного индекса. Другой способ - вообще избавиться от шага Bookmark looknp, создав для запроса подходящий индекс. Чтобы это сделать, необходихю создать некластер)1Ы]1 индекс, состоящий пз столбцов, которые мы хотим вернуть (че.м шире становится нн-декс, тем дороже становится его применение в терминах операций ввода-вьшо-да), или сократить возвращаемые столбцы до тех, которые уже есть в некластерном индексе. В данно.м случае это будет означать получение только столбца OrderDate таблицы, поскольку это едннствеиный ключевог! столбец нснользуе-моуо нами некластерного индекса (которьп1 мы созда.тн на основании критерия в предложегит WHERE). Вот запрос, получающий только столбец OrderDate, и соответствующий е.му план выполиення (рнс. 16.16): 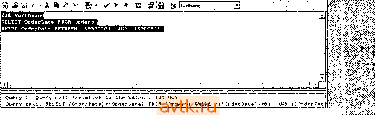 non-tiusleed imM* PhytcM OR**!-.- 1 CPU coK 1И CPU colt Cotl; Subli e чпЛ. l  иЬс. ,<ortn,v:r,c SlL£C OrderOait Ek:j-: UCi?-i WHERE OrderDate BETWEEN :дъ&)ЬьУ tUL ,;-..Eo. Теперь нет необходимости ни и к..астерпом инлеыч.-, ни в таге Воокшагк lookup. Как я уио.мипал ранее, это и;г!ывг1стгл покрытие /аик.ксом - иекластер-ный индекс покрывает запрос, он .можп \лов.и'гворити ein, не обращаясь к таблице или се кластсрно.му индексу. На са.мом лею нек.1асте()щ>1е индексы, которые содержат все столбцы, необхо.цгмые .ianpoc>-, ьстречакпся довольно редко. Однако вы обнаружите, что добавление о.пюго u.ih Д15ух столбцов к неклас-терпо.му индексу, исиользуе.мо.му занросо.чг поз!Ю.!яег е.му иокрьггь запрос, пе становясь чрез.иерио зaтpaтпы^L no.vniiirc, что pacuni])eiuie ключа иекластерно-го индекса ведет к за.медлению .sKXHiiliuaninii. пото.му чю его значения должны быть актуа.чьиьгми, а также это за.\!ед:1яет обработ к}- запроса, пото.\!у что он становится фткзически больп1е -- л.тя его обработки гробуегся больше иа.мяти и операций ввода-вывода. В табл. 16.1 приведены некоторьк; npii.MCiM.i ныражени]!, которые являются и которые не являются аргу.ме!гга.\и1 поиска.
Продолжение Таблица 16.1. Продолжение
Денормализация Очень часто разработчики, мало знакомые с реляционными базами данных, пытаются объяснять плохо спроектированную базу даниых денормализацней для увеличения производительности . Вы не можете точно знать, требуется ли де-нормализання базы данных, если вы снача^ча ее не нормализовали и полностью не протестировали производительность. И даже после этого депор.мализатн! не должна быть nepBbiN! вашим действием - она должна быть последни.м ва)иаи-то.м. Я не реко.мендую дмюр.мализатно в качестве; первоочередного метода решения проблем с производительностью, поскольку это все равно что делать операцию на мозге при головной боли. Как п[1ави.то, при разработке большинства приложений денормынзация не требуется. Если бы в ней была такая необходи-.мость, стандарты проектирования баз данных, которые оттачивались на нр()гя-женпн последних тридцати лет, не стоили бы ничего - что хорошего в стандарте, ecjm ва.м приходится нарушать его, чтобы сделать что-то необ.ходнмое? При .этом денор.мализация ~ это довольно обычный метод увеличения произво2и1тельно-сти запросов в высокоэффективных, высокопроизводительных системах. Устранение единственной операщш соединенн5! нз запроса, обрабататывающего .\тл-Л1ЮНЫ sannceii, может принести существенную вьноду. Поймите, не существует абсолютного стандарта, с помощью которого можно из.мерить нормализацию базы данных. Существуют разные уровни норма^тнзацин, но даже лучшие разработчики создают базы данных, которые могут не отвечать чьи.м-лпбо понятиям о норхгализацнн. Основные рекомендации о Изучите вашу базу данных. Убедитесь, что пони.маете, как она организована с логической точки зрения, а также как приложения ее задействуют. Хорошо пой.ущте, как организована целостность данных в базе данных. Введите избыточных данных в систему делает поддержку целостности данных более стожной и более затратной с точки зрения производительности. Поэтому очень важно знать частоту .модификации данных. Если база данных используется в качестве высокопроизводительного OLTP-приложения, вы .можете обнаружить, что увеличение производнтслььюсти, достигнутое ва.ми за счет Дe;iOpмdЛИJa4я лспорма.-аиицп!!, ()\.ic-t сш-дено па пи- ироо.те.ма.чп! с п1)(Л1звод1!Т(,ЛЫК)Сгыо. спязанн!>1.\П1 с [!()ЛдерлчК(Л1 це.юстпосгп даппь!Х. О Не дено[)ма.п!зупге сразу всю баз}- данных. Работайте с иебольши.\пт логически са.мостоятельиы.\П1 частя.\И1. э Постарайтесь как .\К)жио ра.ч[лие выяс!Н!Ть возможность 1!спользова1И1я вы-чпсляе.мьтч cro.iunoii для иовьниеиия пр()п.звод1Гте;нл1остп. Вы .\в.)л<ете обнаружить, что вычисляе.\пле столоны SQL Server NiorvT обеспечить необходп-.мую нроизводительтюсть вашего прпложети!я, не прибепш к знач]1тельно11 деиормал1тзаипи. О Оп[)елелите даниьн; и тины траизакци!!, соответствуюииш пробле.читым частя.м вашего и])1По;ке1П1я. Воз.молчно, вы обнаружите, что .\южно дополнительно оптимизировать uauni запросы или настроить сервер и решить пробле.\и^1, не прибегая к перепроектированию баз!л данных. о Изучите аппаратные ресурсы вашего сервера. Увеличение физической па.мяти пли увеличение па.мяти SQL Server .может значительно увеличить производительность запросов. Также .может по.чючь добавление и.ти .\юдернизация и|)Оцессоров - особенно если ваши основные запросы иптенпиито используют ресурсы процессора. Са.мое большое увеличение производительности системы обьшно связано с оггги.мизаписГ! дисковой подсистемы. При.мсиенпе более быстрых дисков или увеличение их колнчеслва может увеличить производительность в несколько раз. Напри.мер, вы .чюжете обнаружить, что ир[тмепение R.AID сов.местно с (1)ай.1овы\ит групиа.ми может ренпт. нробле-мы с производи гсльпостью без необходи.мости дснормализатик Основные методы Существует несколько основп!>1х методов, кот()рые .можно иршмепнть для деиор-мализации базы данных в надежде получить увеличение производительности: О создание contrived или виртуальных столбцов; О поддержка избыточных Konnii данных: О использование су.м.мариых таблиц; О вергикпьпое или горизонтальное разде.тенне данных. Спожновычисляемые (contrived) столбцы С.тожиовычпсляе.мьпг пли виртуальный, столбец - ;-)то столбец, создаииьи ! на основании зиачеши ! других столбцов. SQL Server включает нря.мую поддержку слоЖ11овычисляе.\И)1Х столбцов с помощью механизма вычисляемых столбцов. Со; ание вычисляемого столбца избавляет вас от необходихюсти вк;иочать его вы)ажение каждый раз, когда вы выполняете запрос к таблице. Синтаксически :-)то более компактно, кро.ме того, за счет этого результат вычисления выражения сразу становится доступиы.м все.м, кто нснользует эту таблицу. Вычисляемые столбцы определяются с помощью ко.манд CREATE TABLE и ALTER TABLE. Вот пример: USE NorlPrtiPG GO AJER TABLE Groers ADD DeysoSnp AS tASf sfCX Sriopc-uOeie lb МЛIHtN DATED!FKdc.CrderOete.Rscu recDale; llSE null iW SELECT Order Id. COHVERI (charC 10). CrcferOate. 101) AS OroerDate. CONVERГ(спаг( 1С).Reqi.ireoDate. .01) AS ReqjiredOate. CONVERr(charClO).ShippecCate. 101) AS ShippedCate. DaysToShiD ERCM Orde.-s ALTER TABLE Crcers DROP COlUMN DaysoSn GO (результаты сокращены) Orderld OrderDate RequiredDate ShippedDcte DaysToShip
Избыточные данные Наиболее частьи! метод депор.ммпзаши! заключается в при.\!енеиин нескольких конин одних и тех же данных. Например, вы .можете обнаружить, что лучше заранее находить и хранить значения, для получения которых в противном случае пришлось бы использовать соединения. Это у.меньшает работу, которую нужно проделать для получения еобходи,мо11 пн(})ормацнн при выполиеьнш запроса к таблице. Вариант данного .метода заключается в дублировании значении внешних ключей так, чтобы в tnix не было ссылок на другие таблицы. Конечно, необходимо быть осторожным, поскольку этот метод добавляет накладные расходы, связанные с поддержкой целостности данных. Чем больше копий дан11ых у вас есть, те.м больше работы необходн.мо проделывать, чтобы они оставались актуальиы.ми, и те.м больше вероятность ошибок, которые могут нарушить целост1гость базы данных. Вывод - суть реляционной модели: че.м меньше копий неключевых данных, те.м легче их поддерживать и тем меньше вероятность того, что в случае возникновения проблем их целостность будет нарушена. Вот пример, а котором в таблину titleauthor базы данных pubs добавляются столбцы, содержащие н.мя и фамилию автора из таблицы authors: ALTER TABLE titleautnor ADD аи 1пате varcnar(40) NULL. au fname varchar(20) NULL UPDATE t SET au lname=a,au lname, au f name-a. aj fname FROM titleauthor t JOIN authors a ON (t.au id=a.aujd) GO SELECT * FROM titleauthor GO ALTER TABLE titleauthor DROP COLUMN eujneae ALTER TABLE titleauthor DROP COLUMN au fname 1 ... 34 35 36 37 38 39 40 ... 55 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© 2004-2025 AVTK.RU. Поддержка сайта: +7 495 7950139 в тональном режиме 271761
Копирование материалов разрешено при условии активной ссылки. |
 Экструзия композитов
Экструзия композитов Угловые шкафы
Угловые шкафы Искусственная кожа
Искусственная кожа Детская кроватка
Детская кроватка Мебель для ванной
Мебель для ванной Выбираем мебель
Выбираем мебель Ткань для мебели
Ткань для мебели Подъемная кровать
Подъемная кровать Шторы для дома
Шторы для дома Поролон
Поролон